Breakdown of Large Language Diffusion Models
Authors: Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, Chongxuan Li.
Arxiv
Project Page
GitHub repo
Table of Contents:
Introduction
What is now proved was once only imagined.
—William Blake
The current LLM space is dominated by Autoregressive models - ARMs which are based on the Transformer Architecture. Authors of this paper challenge this and subsequently propose LLaDA - Large Language Diffusion with mAsking, a diffusion model.
The authors argue that scalability of ARMs is a direct result of the interplay between model size, data size and Transformers induced by the generative principles i.e. optimizing a model distribution through maximum likelihood estimation in-order to achieve the ground truth distribution using an equation as below:
and not unique to ARMs and the boom of Diffusion models in image generation is another clear example of it. Another great argument authors add to this debate is that any large-scale probabilistic model with proper conditioning can show instruction-following & in-context learning behaviour.
PS: If you are new to Diffusion or finding the math hard to follow, I have listed some videos & blogs to help you out! - Resources
Approach
While ARMs rely on next-token prediction methodology that defines model distribution using an equation such as below:
LLaDA defines the model distribution using forward & reverse process as seen in denoising diffusion models.
In the forward process we mask the input tokens independently until the whole sequence is fully masked at where
In reverse process our goal is to recover the unmasked sequence from the masked sequence as moves from to .
The reverse process is done using a parametric model that takes an input and simultaneously predicts all masked tokens, the said model is trained using a cross-entropy loss computed on the masked tokens using following equation:
M - masked tokens
- loss is computed only for masked tokens
for normalization
The authors have used the Transformer Architecture for the mask-prediction task with the major change being that there is no causal mask added to the attention block as they want the model to see the entire input sequence. In essence they have used bi-directional transformer. They have trained two LLaDA models: LLaDA 1B and LLaDA 8B, both of which closely follow the LLaMA architecture and for evaluation purposes they have used two ARMs as well with size 1B and 7B, detailed specifications:
| ARM Baseline 1B | LLaDA 1B | ARM Baseline 7B | LLaDA 8B | |
|---|---|---|---|---|
| Layers | 22 | 22 | 28 | 32 |
| Model Dimensions | 2048 | 2048 | 4096 | 4096 |
| Attention Heads | 32 | 32 | 32 | 32 |
| Vocabulary Size | 126,464 | 126,464 | 126,464 | 126,464 |
| FFN dimension | 5634 | 5634 | 13,440 | 12,288 |
| Key/Value heads | 4 | 4 | 8 | 32 |
| Total parameters | 1.49B | 1.49B | 6.83B | 8.02B |
| Non-embedding parameters | 0.97B | 0.97B | 5.80B | 6.98B |
The main reason behind training a new model while they surely could have just used a pre-trained open-source ARM is that it wouldn’t have been a fair comparison, since there might be a difference in the training data, training FLOPs, SFT, alignment and much more. Also they didn’t train a 8B ARM to compare with LLaDA 8B and have instead used a “previously trained” 7B ARM. (due to computational resource constraints T_T)
They have ensured consistency in most of the hyper-parameters across LLaDA and ARM and have used multi-head attention for simplicity.
Using Warmup-Stable-Decay 1 they have pre-trained the LLaDA models on 2.3 trillion tokens, comprising of high-quality code, math and multi-linguial data apart from general text, by linearly increasing the learning ratefrom to for the first iterations and maintaining at till tokens have been processed after which they decayed it and kept it constant for the next token followed by linearly decreasing it to for the last tokens. They maintained a fixed sequence length of tokens while setting the length of of the pre-training data to a random length, uniformly sampled from , in order to enhance the model’s capability to handle variable length data. The total computational cost came out to be million GPU hours
For Supervised Fine-Tuning (SFT) they have used million pairs consisting of prompt () and response (). Essentialy a concatenation of and works as pre-training data while a concatenation of and works as the masked version since we are only masking the tokens of . They have used the same scheduling strategy as in pre-training stage.
One interesting thing done by them in SFT was to append tokens to the end of short-sequences in each mini-batch. This not only ensures equal sequence lengths across all the data points in a mini-batch but is also very important in making the model “learn” to control length of the sequence by generating and hence adjusting response length according to the prompt. (The tokens are removed from the output during sampling.)
For inference, we feed both and , where , to the mask predictor and predict all masked tokens. Yet this isn’t what we want, since we want to gradually unmask tokens and not once at all in a single step.
Think of it as denoising a latent vector in a diffusion based image generation model in a single sampling step rather than multiple step i.e. the model tries to predict the distribution in a single step rather than gradually arriving at it in multiple sampling steps. So we reintroduce the noise in the tokens by remasking i.e. for we remask of the predicted tokens at current step. Authors have explored two remasking strategies in the paper which I think would be better to explain along with the results.
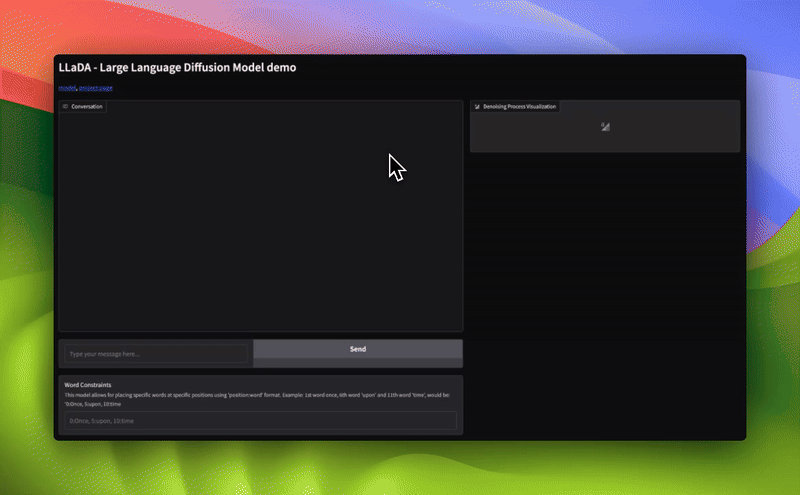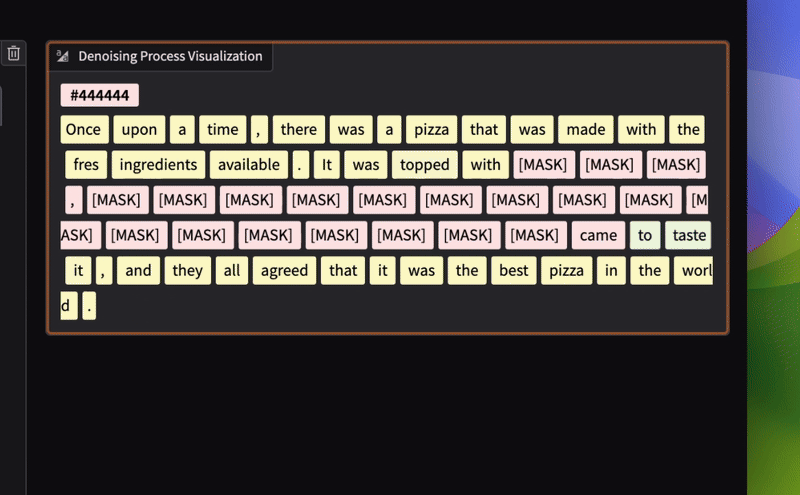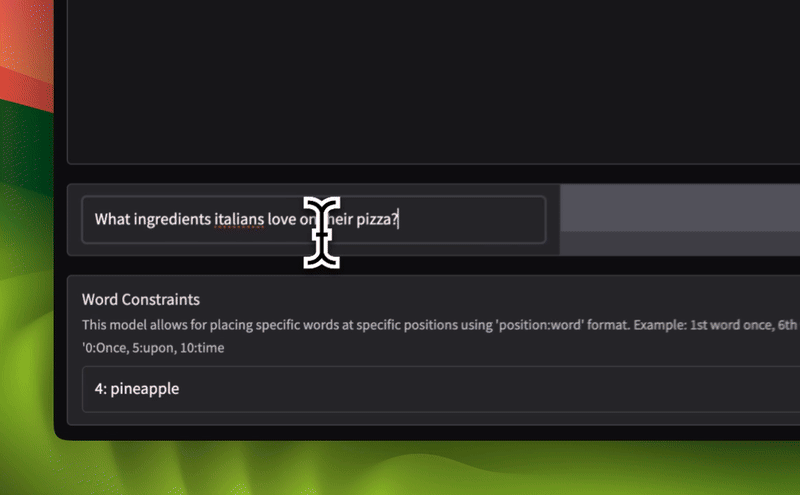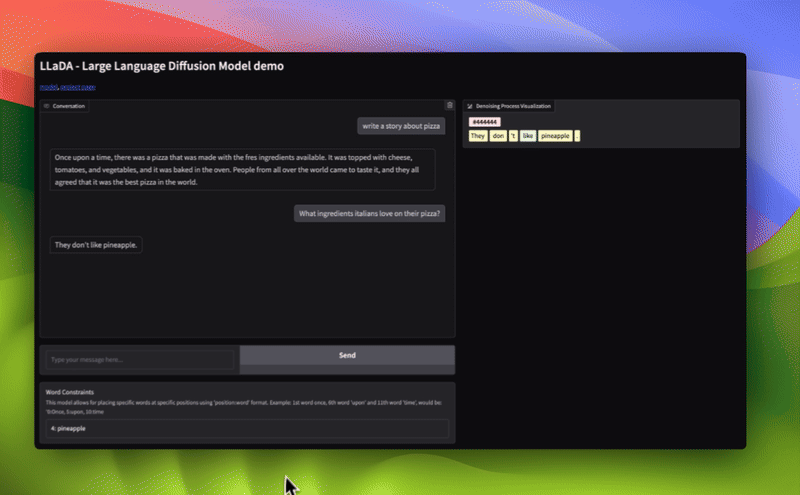
inference demo of LLaDA made by apolinário
Results
To show capabilities of LLaDA authors have compared it with similarly sized ARM models such as LLaMA3-8B, LLaMA2-7B, Qwen2-7B, Gemma2-9B and others.
Benchmarks results of pre-trained models:
| LLaDA 8B | LLaMA3 8B | LLaMA2 7B | Qwen2 7B | Qwen2.5 7B | Mistral 7B | Deepseek 7B | |
|---|---|---|---|---|---|---|---|
| MMLU | 65.9 (5) | 65.4 (5) | 45.9 (5) | 70.3 (5) | 74.2 (5) | 64.2 (5) | 48.2 (5) |
| BBH | 49.8 (3) | 57.6 (3) | 37.3 (3) | 62.3 (3) | 70.4 (3) | 56.1 (3) | 39.5 (3) |
| ARC-C | 47.9 (6) | 53.1 (6) | 37.0 (6) | 60.6 (25) | 63.7 (25) | 60.0 (25) | 48.1 (0) |
| Hellaswag | 72.5 (0) | 79.1 (0) | 66.0 (0) | 82.0 (0) | 85.0 (0) | 83.3 (0) | 75.4 (0) |
| TruthfulQA | 46.4 (0) | 44.0 (0) | 35.2 (0) | 52.4 (0) | 56.4 (0) | 42.2 (0) | 70.0 (0) |
| WinoGrande | 74.8 (5) | 77.3 (5) | 69.3 (5) | 75.4 (5) | 75.9 (5) | 78.4 (5) | 77.0 (5) |
| PIQA | 74.4 (0) | 80.6 (0) | 79.1 (0) | - | - | - | 79.2 (0) |
| GSM8K | 70.7 (4) | 53.1 (4) | 14.3 (4) | 80.2 (4) | 85.4 (4) | 36.2 (4) | 17.4 (8) |
| Math | 27.3 (4) | 15.1 (4) | 13.4 (4) | 43.5 (4) | 49.8 (4) | 16.4 (4) | 6.0 (4) |
| GPQA | 26.1 (5) | 25.9 (5) | 25.7 (5) | 30.8 (5) | 36.4 (5) | 24.7 (5) | - |
| HumanEval | 33.5 (0) | 34.2 (0) | 12.8 (0) | 51.2 (0) | 57.9 (0) | 29.3 (0) | 26.2 (0) |
| HumanEval-FIM | 73.8 (2) | 73.3 (2) | 26.9 (2) | 72.6 (2) | 73.3 (2) | 59.6 (2) | 31.2 (2) |
| MBPP | 38.2 (4) | 47.4 (4) | 18.4 (4) | 64.2 (4) | 74.9 (0) | 51.1 (0) | 39.0 (3) |
| CMMLU | 69.9 (5) | 50.7 (5) | 32.5 (5) | 83.9 (5) | - | - | 47.2 (5) |
| C-Eval | 70.5 (5) | 51.7 (5) | 34.0 (5) | 83.2 (5) | - | - | 45.0 (5) |
Numbers in parentheses are the number of shots used for evaluation.
The results clearly shows that LLaDA-8B is on par with LLaMA3-8B on most of the metrics and has even surpassed LLaMA2-7B but clearly lags behind Qwen2-7B and Qwen2.5-7B by a huge margin.
Benchmarks results of post-trained models:
| LLaDA 8B | LLaMA3 8B | LLaMA2 7B | Qwen2 7B | Qwen2.5 7B | Gemma2 9B | Deepseek 7B | |
|---|---|---|---|---|---|---|---|
| MMLU | 65.5 (5) | 68.4 (5) | 44.1 (5) | - | - | - | 49.4 (0) |
| MMLU-pro | 37.0 (0) | 41.9 (0) | 4.6 (0) | 44.1 (5) | 56.3 (5) | 52.1 (5) | - |
| Hellaswag | 74.6 (0) | 75.5 (0) | 51.5 (0) | - | - | - | 68.5(-) |
| ARC-C | 88.5 (0) | 82.4 (0) | 57.3 (0) | - | - | - | 49.4 (-) |
| GSM8K | 78.6 (4) | 78.3 (4) | 29.0 (4) | 85.7 (0) | 91.6 (0) | 76.7 (0) | 63.0 (0) |
| Math | 26.6 (0) | 29.6 (0) | 3.8 (0) | 52.9 (0) | 75.5 (0) | 44.3 (0) | 15.8 (0) |
| GPQA | 31.8 (5) | 31.9 (5) | 28.4 (5) | 34.3 (0) | 36.4 (0) | 32.8 (0) | - |
| HumanEval | 47.6 (0) | 59.8 (0) | 16.5 (0) | 79.9 (0) | 84.8 (0) | 68.9 (0) | 48.2 (-) |
| MBPP | 34.2 (4) | 57.6 (4) | 20.6 (4) | 67.2 (0) | 79.2 (0) | 74.9 (0) | 35.2 (-) |
Overall a good start given that LLaDA hasn’t gone in any other post-training, except vanilla SFT, like other models which have gone through RL as well.
Reversal Reasoning
One of the major short-coming of ARMs is reversal curse 2 i.e. if a model is trained on a sentence like “A is B” it will not automatically generalize to the reverse direction “B is A”. To analyze the performance of LLaDA on this authors made a dataset of 496 famous Chinese poem sentence pairs. Here, the model is asked to generate subsequent line or the preceding line given a sentence from the poem. Generating subsequent line shows forward generation capabilities while generating preceding line shows backward or reversal generation capabilities, we focus on the later.
Results in Poem Completion Task:
| Forward | Reversal | |
|---|---|---|
| GPT-4o (2024-08-06) | 82.7 | 34.3 |
| Qwen2.5 7B Instruct | 75.9 | 38.0 |
| LLaDA 8B Instruct | 48.8 | 42.4 |
Although the difference isn’t as huge as one might expect, it’s important to weigh in the fact that LLaDA is just an 8-billion-parameter model and yet it’s outperforming the “SOTA” GPT-4o model, whose parameter count is speculated to be in the trillions3. In that sense, it’s a major leap. I believe the gap in the Forward task can easily be closed by scaling up the model size. Whether the Reversal performance will hold up—or even improve—as the model scales remains to be seen.
Remasking Strategies
As discussed earlier, we need to remask tokens at each step of generation. For this authors have proposed two strategies as follow:
→ Lowest confidence remasking
- We only remask those tokens that the model was least confident about, making sure that we preserve the confident outputs and focus on parts which the model is uncertain about.
→ Lowest confidence & semi-autoregressive remasking
- One of the major disadvantage of the previous method is that it wouldn’t work well for the post-trained model since in post-training the model becomes more confident about predicting token and we would get an excessively high and unnatural occurrence of tokens in the output.
- Hence, to overcome the said problem the authors have introduced this new approach in which they divide the whole sequence into blocks. Each block is generated from left to right and the reverse process is applied individually on each block.
Ablation on Remasking:
| LLaDA 8B Base | LLaDA 8B Instruct | |
|---|---|---|
| Randomly remasking | 52.3 | 72.0 |
| Lowest confidence remasking | 64.7 | 12.9 |
| Lowest confidence & semi-autoregressive remasking | 64.4 | 73.8 |
GSM8K accuracy
There is little (or no difference at all) in performance of the base model for both strategies since are not padded in pre-training. However, a clear huge improvement can be seen for the instruct model by applying the strategy.
Ablation on Generated Length:
| Length | LLaDA 8B Base | LLaDA 8B Instruct |
|---|---|---|
| 256 | 62.5 | 75.3 |
| 512 | 64.7 | 73.8 |
| 1024 | 65.9 | 75.3 |
GSM8K accuracy
Both models, base and instruct, show minimal difference in performance across varying length. The base model adopts lowest-confidence remasking strategy while the instruct model adopts semi-autoregressive sampling with a block length of .
Analysis of Sampling Steps:
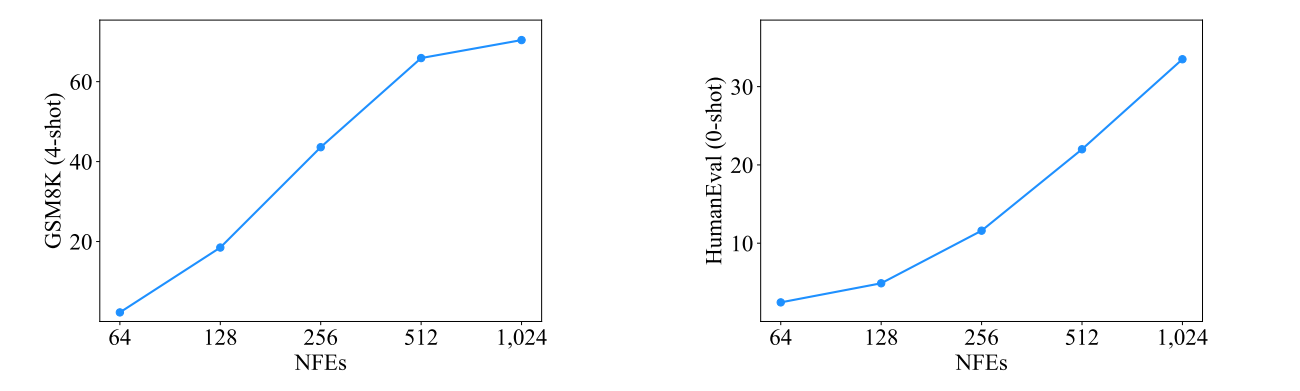
The authors kept the answer length fixed at 1024 and increased sampling steps - Number of Function evaluations (NFEs) - which improved model performance in both GSM8K and HumanEval datset. ( more compute leads to more performance? )
Conclusion / my thoughts
I feel the LLM space has felt a bit saturated over the past few months and this paper is a breath of fresh air. Although there is a need to test the performance of such diffusion based text models when they are scaled up to the size of 100s of billion and maybe even trillion of parameters - do they hold up against quality given by ARMs?
Apart from delivering quality, such new diffusion based text models need another important thing to make a name for themselves in current AI space - cheap to run. There is a whole ecosystem built around optimizing inference of ARMs, a similar ecosystem has to be built for diffusion based text models like inference libraries, fast pre & post training frameworks etc. Hopefully someone will do it.
Please let me know what you think about this new approach, and also share your feedback about this blog, via contact
Thanks for reading!
Thanks to my good friends Moksh & Taha for reviewing this blog!
Resources
→ Why does Diffusion work Better than Auto-Regression / video~20min
→ Diffusion Models: DDPM / video~32min
→ Denoising Diffusion Probabilistic Models / video~29min
→ Step by Step visual introduction to Diffusion Models / article~63min
Footnotes
Shengding Hu et al., “MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies,” 2024, https://arxiv.org/abs/2404.06395.↩
Lukas Berglund et al., “The Reversal Curse: LLMs Trained on ‘A Is B’ Fail to Learn ‘B Is A,’” 2024, https://arxiv.org/abs/2309.12288.↩
Hacker News Community, “Speculation on GPT-4o’s Parameter Count and Performance,” 2023, https://news.ycombinator.com/item?id=36413296.↩